
Biotech needs world models
Learning to simulate like a toddler
This past weekend I came out of academic retirement and attended my first conference since finishing my PhD: SITC. It was a fascinating and humbling and exhausting experience, and I came away with a healthy mix of imposter syndrome and optimism about how quickly things could change as the cogs of machine learning and biology meet. I attended the conference in large part to speak about that issue, and ended up giving a talk on the coming role of AI in cancer immunotherapy. In that talk, I proposed a vision for how self-supervised machine learning could help improve clinical trial outcomes for patients, and I want to share the rough sketch of those arguments here in written form.
The big glaring problem in cancer immunotherapy is that we don’t know ahead of time which patient will benefit most from which drug. We know that some patients have miraculous responses to some drugs, but most won't. Consider this survival curve for patients receiving pembrolizumab in non-small-cell lung cancer, arguably one of the more successful cases of trying to predict benefit of treatment.
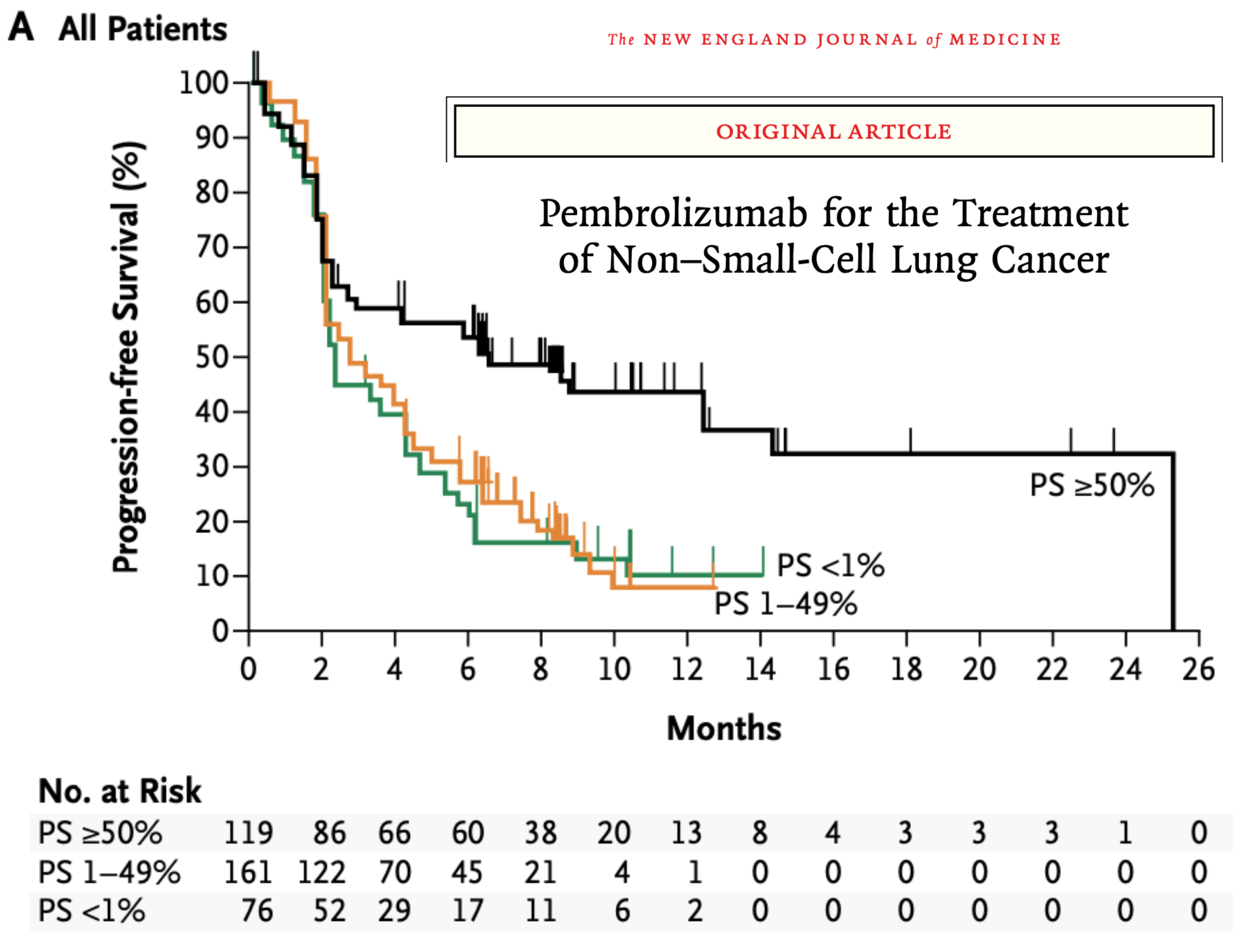
In these kinds of plots, you want the line to be flat and high – ideally all patients make it beyond 2 years post-treatment without progression of their tumors. But the data are clearly… not that. The black curve represents the best case scenario here: a sample of your tumor is removed and analyzed, and if enough tumor cells express the PD-L1 protein (whose receptor PD-1 is being targeted by pembrolizumab), you get sorted into the “higher likelihood of response” group. And there is an effect there! Compare the black line (>50% of tumor cells thought to be susceptible) compared to the orange and green (1-49% and <1%, respectively). But even that black line is saturating around 35%, meaning that 65%+ of patients are seeing tumor progression after the first year of treatment.
There are effectively only two ways out of this state of affairs: either find a new drug that will lead to better responses in the same patient population, or find a better way to sort patients into “likely responder” and “likely non-responder” groups. The latter is referred to as patient stratification, and it’s the fastest path available to us for improving outcomes ASAP. This is what my colleagues and I have been focused on for the past few months, and I want to explain the approach we’re betting on.
A toddler could do it
To explain our perspective, I want to go back to basics: all the way back to preschool. Consider the task of “response prediction” for a stack of blocks that a four year old might have assembled. The tower (analogy: tumor) is sitting on a stool (analogy: patient tissue) and I want to know if throwing a ping pong ball at the tower (analogy: pharmacological intervention) is going to successfully knock the tower over. With the power of your big beautiful brain, you can run a quick mental simulation and guess “eh, probably not going to knock over the tower with a ping pong ball”. In fact, I suspect you’re running simulations like this all the time, often without realizing you’re doing it.
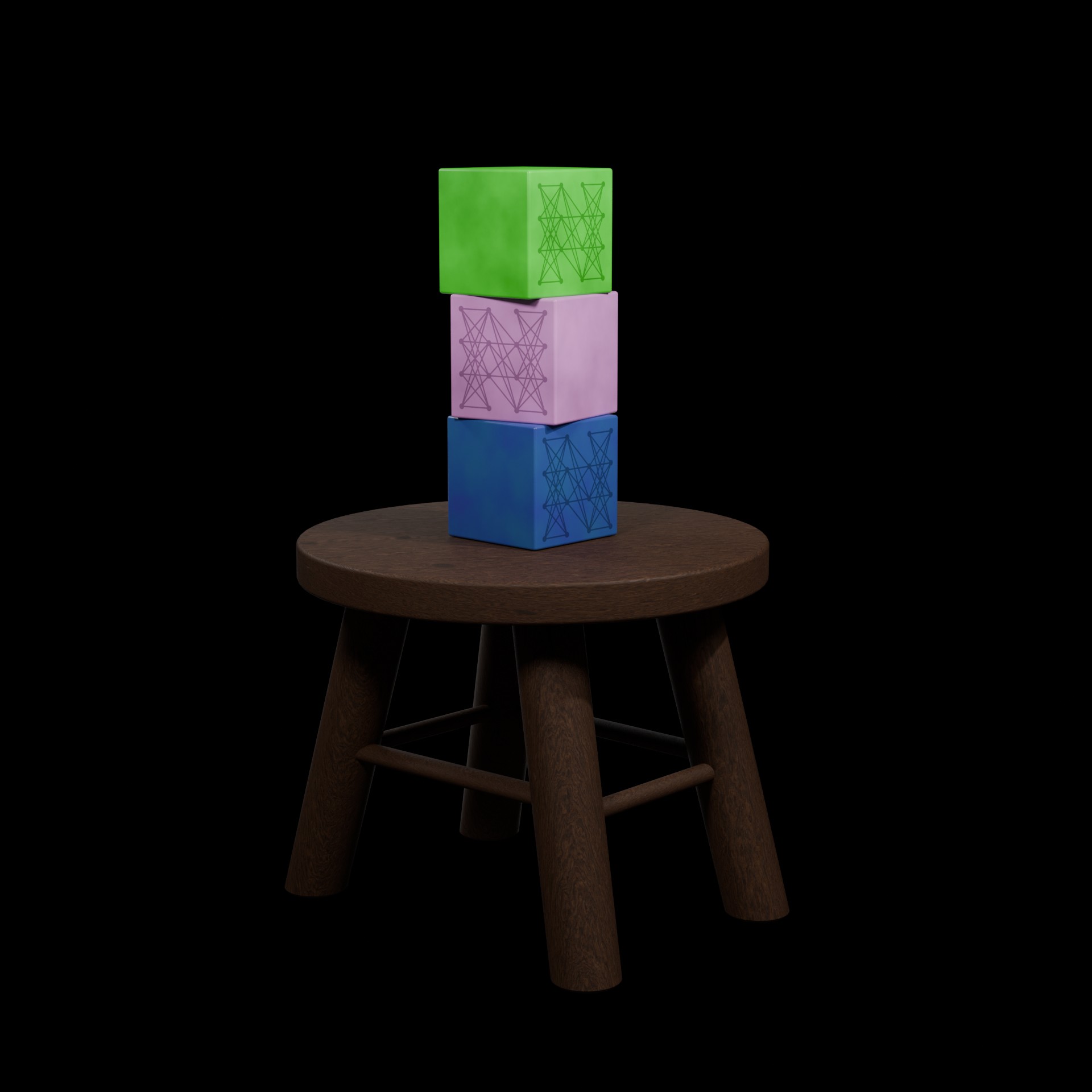
So when I present you with some increasingly wacky situations, you can run your mental simulation and make very strong guesses about whether the tower of blocks will fall over or not. These particular situations were not chosen at random: some tumors may be more intrinsically susceptible to a given perturbation (left), tumors develop “immune escape” mechanisms that shield or disguise them from the immune cells hunting them down (middle), and some treatments aim to use a combination of therapeutic agents that have an effect greater than the sum of their parts (right), like a cat that likes to chase ping-pong balls and might knock the tower over in the process.

Consider that your ability to simulate outcomes here can generalize to other types of perturbations. You can make a very strong guess about what will happen if, instead of throwing a ping pong ball, I choose to shake each stool instead, or point an industrial-strength fan at the towers, or drop an anvil from 100 feet in the air, and so on.
Now despite my masquerading as a cancer immunologist, I’m still a neuroscientist at heart, and it’s worth asking the cognitive neuroscience question being begged here: how does your brain do this? I mean, literally, what’s happening in your skull that allows you to make these predictions? To a very rough first approximation, pixels are hitting your retina, your cortex computes some nonlinear function of input, and the result goes to your motor cortex so you can say “tower gonna fall.” The open neuroscientific question relates to why and how that nonlinear computation occurs, and to say that there are many competing theories is an understatement. One reasonable proposal is that your brain has a “world model”, which I’ll define like this:
a world model is a system that can compute the likelihood of some future state of the world, conditioned on the existing state of the world and future actions that can be taken
This is a somewhat unsatisfying definition for a neurd, since it guesses at what the brain is doing rather than how the brain does that thing. But if you take it at face value, the world model hypothesis suggests that the way you’re predicting the fate of these precarious block towers – the effect of the computation playing out in your brain – is the running of a mental simulation. That simulation is informed by decades of experience you have in the world, starting from preschool age and being reinforced every day as you observe and interact with physical dynamics in the world around you. Even by the age of four, you have already learned an implicit model of the world, and can make sophisticated predictions about what will happen in novel scenarios like a-cat-chasing-a-ping-pong-ball-thrown-at-a-block-tower-with-a-glass-shield-on-a-wooden-stool.

I think we should pay very close attention to this remarkable capability, and mimic this setting as closely as possible in cancer immunotherapy: first build a world model (i.e. a simulator) by observing a huge unlabeled dataset, then run many simulations to predict outcomes in specific never-before-seen scenarios. The bet is that, for a given therapy, patient-specific simulations will look different for patients that will respond to a therapy than from non-responders.
If I’ve done my job well up to this point, you should be nodding vigorously and muttering “yes” and “absolutely” under your breath, but I should very briefly describe the alternatives to this framework. One approach that feels very Scientific is to form a hypothesis a priori about what should separate responders from non-responders in a given clinical trial, then test that out. That’s basically what happened with that pembrolizumab survival curve I showed above; enough said about the efficacy of this approach. The other alternative is to run a small clinical trial, then analyze only the data from that trial to fish for differences between responders and non-responders that may help guide future patient stratification in the next trial. This is a perfectly reasonable approach, except that 1) it’s clearly not what the brain is doing, and 2) you wind up in situations that are statistically precarious due to inescapably small sample sizes. In my block example, this would be like carefully examining towers that fell and towers that didn’t fall, and realizing that stable towers all have a bottom block that is blue. Of course its blue-ness has no causal impact on the stability of the structure, but your analysis doesn’t know that.
This is why I'm betting on world models: it's the only approach where I see both an existence proof (the brain) and a clear path to making use of limited clinical trial data.
How do you use a world model to improve clinical trial outcomes?
The deep question lurking in the world model hypothesis relates to actually learning that model. How do you build a neural network, artificial or biological, that can make accurate predictions of future states given observations? To be honest I think this is very far from solved, but the answer is almost certainly to do some sort of self-supervised learning from a large unlabeled corpus of training data. If you want to read more about our approach to building and using these models at NOETIK, I'd point you to our technical report on one such model, OCTO-vc, and to a series of posts by Abhishaike Mahajan: "How do you use a virtual cell to do something actually useful?".
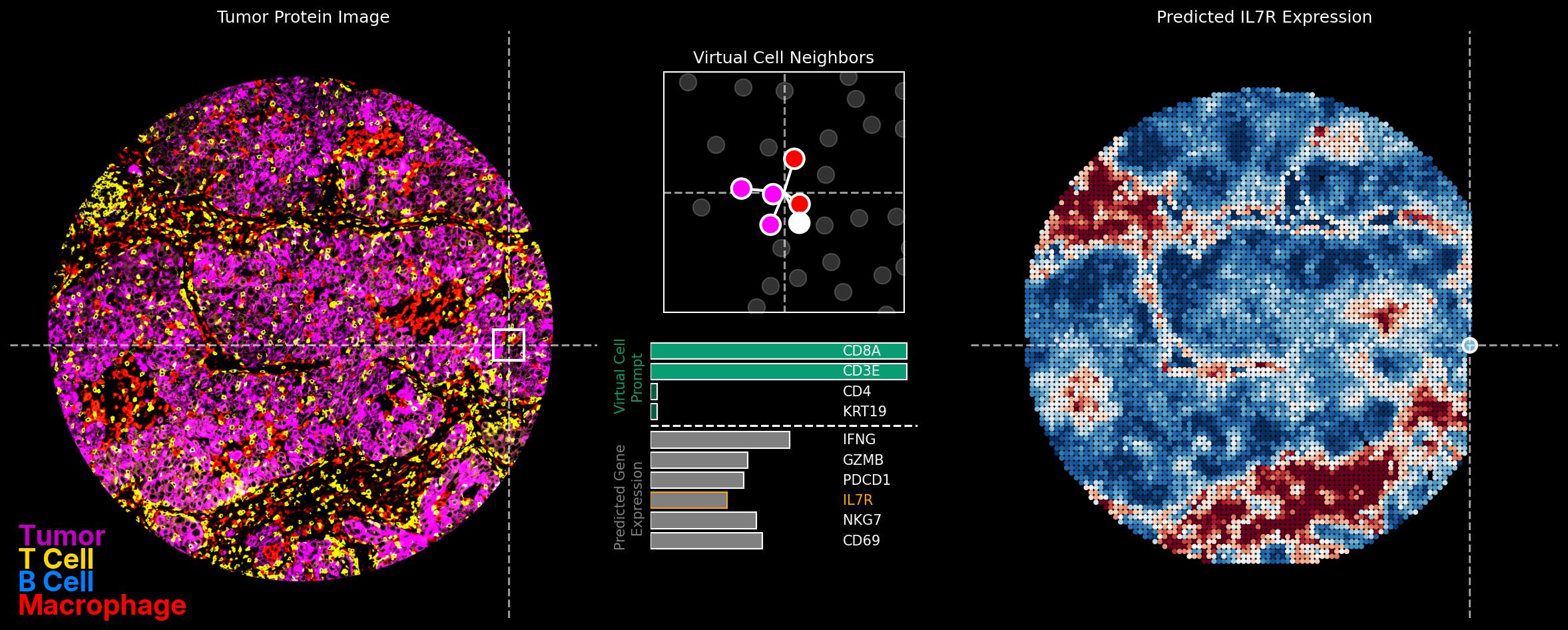
The first post in that series describes the strategy for applying world models to scarce clinical data. We pre-train our models on a mountain of unlabeled data, then position the few points of clinical data within that space and look to see where responders lie. The important points in my opinion are that: 1) this process is fast for new data -- pretraining a model is slow, but inference on clinical data is measured in minutes or hours -- and 2) that nothing about this process is tailored to, or overfit to, the clinical data. This is the best protection we have against discovery of spurious correlations.
I (obviously) believe there's a lot of reason for optimism around the role of world models in cancer immunotherapy, but this still feels to me like the v0 alpha pre-release version of what we'll be using in a few months time. I expect in the future:
- Models used for patient stratification will depend only on H&E images (cheap and easy to acquire) at inference time, a direction we've invested heavily in and will share more about soon
- The breadth and depth of the pretraining data will continue to grow and span a wider range of cancer types
- Our ideas for which simulations to run will become better targeted. This probably warrants a whole post of its own, lots of interesting possibilities here.
In parallel, I expect that researchers working on the design of world models for other domains (e.g. video) will find approaches that translate back into AI-for-bio, and vice-versa.
A final point I can't resist making: your own mental world model might be simulating a different kind of outcome as you read this, estimating the likelihood that this approach will actually work in cancer therapy. If you're close to 0% or 100% in that estimate, get in touch! I'd love to hear from you.